2021年9月24日 (金曜日)
18:00:01 # Life 標準偏差を計算。 RとC++とRustとJavascriptで同じような値が出るようにとやってみ たところ値が合わなくてなんでだろうと思って調べていたらRでは stddevはn-1で割っていることがわかったので調べてなんかサンプ ルと母集団の場合で違うということをなんか薄っすらと思い出して めんどくさいなぁと思った。なんでこうなっていたのか。 nが十分大きいと気にならないのだけどnが小さいときとか挙動が正しいことを確認するためにユニットテストを書いてみたりすると気になる。
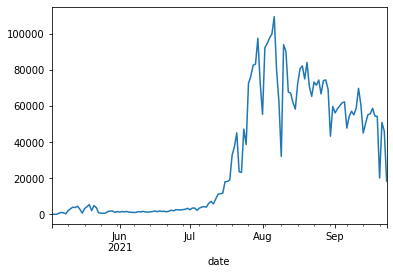
18:41:32 # Life pandasでndjson処理。 東京都のワクチン接種の速度はどうなっているのかなとおもったので調べてみた。 都道府県別のデータがNDJSON形式で提供されている。 もっと難しいかなと思っていたので拍子抜けしたのだがPandasのread_jsonは便利なことに行区切りのJSONというのを処理できるようになっているので(jsonl?)それを使えば良さそう。 とりあえず簡単にグラフができました。よかったよかった。二度目のワクチン接種している人の数なのかこれ。 最初に接種し終わっている65歳以上を除外したグラフがほしかったのでこれで良いのかも。 tokyo_vacc.groupby(tokyo_vacc['date']).sum()['count'].cumsum().plot()にしたら累積数になった。 東京都の人口1325万人、65歳以上は309万人、65歳以下はざっくりというと1000万人くらいか。そのうちの400万人くらい接種しているのかな。現在400万人くらいで、5万人くらいのペースで接種している、と。
vacc_per_pref = pandas.read_json('https://vrs-data.cio.go.jp/vaccination/opendata/latest/prefecture.ndjson', lines=True)
# 東京都はprefecture 13
tokyo_vacc = vacc_per_pref[vacc_per_pref['prefecture']==13]
tokyo_vacc = tokyo_vacc[tokyo_vacc['age']=='-64']
tokyo_vacc = tokyo_vacc[tokyo_vacc['status']==2] # 2nd doze
tokyo_vacc = tokyo_vacc[tokyo_vacc['medical_worker']==False]
tokyo_vacc.groupby(tokyo_vacc['date']).sum()['count'].plot()